Gemini Embedding 2와
음성 검색 파이프라인의 변화 가능성
Google 최초의 네이티브 멀티모달 임베딩 모델이 음성 RAG 파이프라인의 STT 의존도를 낮출 수 있을지 분석합니다.
STT 없이 음성을 직접 벡터로 — 검색 파이프라인이 단순해질 수 있다
2026년 3월 10일 발표된 Gemini Embedding 2는 텍스트, 이미지, 비디오, 오디오, PDF를 하나의 통합 임베딩 공간에 매핑하는 Google 최초의 네이티브 멀티모달 임베딩 모델입니다. 음성 RAG 관점에서 가장 주목할 점은 검색 인덱싱 단계에서 중간 STT 변환 없이 오디오를 직접 임베딩할 수 있다는 것입니다.
기존 검색 파이프라인: 음성 → STT(Whisper 등) → 텍스트 청킹 → 텍스트 임베딩 → 벡터DB
새 검색 파이프라인: 음성 → 오디오 청킹 → 바로 임베딩 → 벡터DB
※ 감사·자막·요약·규정 준수 등 다른 목적의 STT는 여전히 필요할 수 있습니다.
검색/인덱싱 단계에서 STT 의존도가 낮아짐으로써 레이턴시 감소, 텍스트화 과정에서 손실되던 음성 신호 활용 가능성, 비음성 오디오 처리 가능이라는 세 가지 이점이 기대됩니다. 다만 임베딩이 구체적으로 어떤 부수언어 정보(톤, 화자 정체성 등)를 어느 수준까지 보존하는지는 공식 문서에서 명시적으로 보장하지 않으며, 추가 검증이 필요합니다.
주요 스펙 요약
모든 입력 제약이 "한 청크 단위"에 최적화되어 있어, 장시간 오디오는 반드시 청킹 전략이 필요합니다. 오디오 80초 제한은 콜센터 통화(수 분~수십 분)를 감안했을 때 VAD 기반 분할이 사실상 필수적입니다.
음성 RAG 검색 파이프라인 비교
검색 인덱싱/검색 단계에 한정하면 STT 의존도가 크게 낮아질 수 있습니다. 텍스트 변환 과정에서 사라지던 음성 신호(억양, 감정 등)를 임베딩이 활용할 가능성이 열리는 것도 의미 있는 변화입니다.
다만 프로덕션 환경에서는 감사 로그, 자막 생성, 요약, UI 표시, 규정 준수 등 다양한 이유로 transcript가 계속 필요할 수 있어, "STT가 사라진다"보다 "RAG 검색 경로에서 STT 의존도가 낮아진다"가 더 정확한 표현입니다. 또한 오디오 청킹의 난이도는 텍스트 청킹보다 높습니다. 오디오는 발화 중간에 잘리면 임베딩 품질이 크게 떨어질 수 있습니다.
성능 벤치마크
아래는 Google이 공개한 Gemini Embedding 2의 멀티모달 벤치마크 비교 테이블입니다. 기존 멀티모달 임베딩(multimodalembedding@001), Amazon Nova 2, Voyage Multimodal 3.5와 비교됩니다.
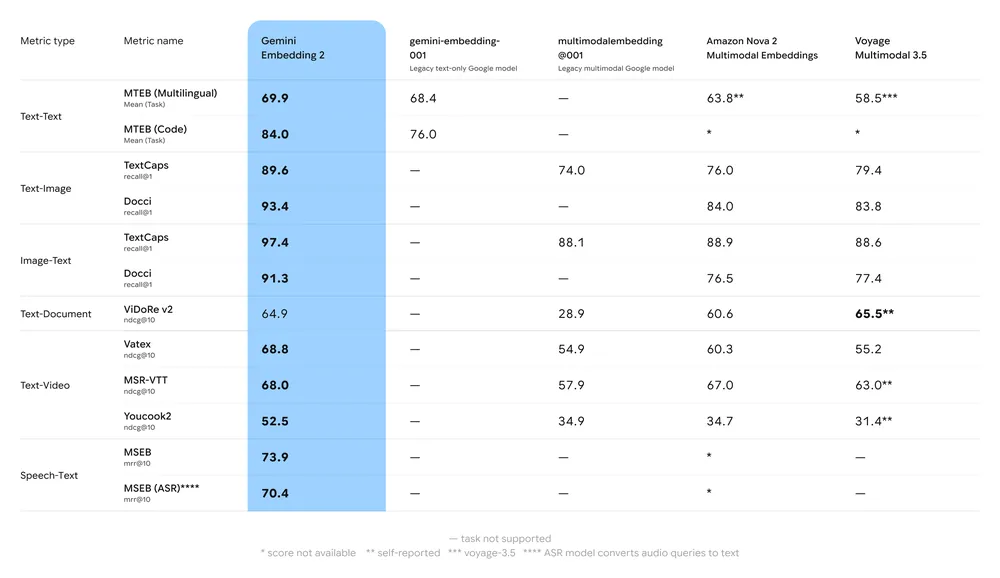
주목할 점은 Speech-Text 카테고리입니다. MSEB(mrr@10) 73.9, MSEB ASR(mrr@10) 70.4를 기록했는데, 비교 대상인 Amazon Nova 2와 Voyage Multimodal 3.5 모두 이 태스크를 지원하지 않거나 점수가 공개되지 않았습니다. 단, Amazon Nova Multimodal Embeddings도 오디오를 포함한 멀티모달 임베딩을 Bedrock에서 제공하고 있어 "업계 최초"라기보다는 Google 스택에서의 첫 본격적 선택지로 보는 것이 정확합니다. 다만 Speech-Text 벤치마크를 공개 비교할 수 있는 수준에서는 현재 앞서 있습니다.
텍스트-텍스트 영역에서도 MTEB Multilingual 69.9, MTEB Code 84.0으로 기존 gemini-embedding-001 대비 의미 있는 향상을 보이며, 이미지·비디오 크로스모달 검색에서는 경쟁 모델을 10~15포인트 이상 앞서고 있습니다.
도입 시 고려사항
결론
Gemini Embedding 2는 Google 스택에서 음성 검색·분석 단계의 STT 의존도를 낮추는 첫 본격적 옵션입니다. RAG 검색 파이프라인에서 STT라는 구조적 병목을 우회할 수 있는 가능성을 열어주며, 특히 Speech-Text 크로스모달 벤치마크에서 공개 비교 가능한 점수를 제시한 몇 안 되는 상용 모델입니다. 다만 업계 전체 최초 사례이거나 모든 Voice Agent에서 STT가 사라진다는 뜻으로 보긴 아직 이릅니다.
오디오 80초 제한, Public Preview 상태, API 의존성(폐쇄망 미지원), 그리고 부수언어 정보 보존 수준에 대한 공식 보장 부재 등 프로덕션 적용까지는 검증이 필요합니다. 현 시점에서는 PoC 수준의 파일럿을 통해 기존 STT+텍스트 임베딩 파이프라인 대비 검색 품질·레이턴시·비용을 비교 평가하는 것을 권장합니다.